
CRISTIAN GAMÓN
"Analista de datos enfocado en generar valor de negocio a través del análisis y la ciencia de datos."

Excel | Python | SQL | Power BI | Tableau
Manejo de librerías de Python claves para el análisis de datos como Pandas, NumPy y Scikit-learn, entre otras.
Desarrollo end-to-end de modelos de Machine Learning con enfoque en impacto empresarial.
Desarrollo del ciclo completo del análisis de datos: recolección, limpieza, análisis y comunicación de resultados.
Dominio de SQL para realizar búsquedas, uniones y agregaciones en bases de datos relacionales.
Proyectos
Data Analytics & Machine Learning
MODELOS DE ML PARA HERRAMIENTA DE SCORING BANCARIO
PYTHON | SCIKIT-LEARN | STREAMLIT
La entidad financiera La Butxaca nos encarga la actualización de su modelo de riesgo crediticio tras observar un incremento de la morosidad de sus clientes.Insights:
Desarrollamos 3 modelos de ML capaces de obtener la pérdida esperada en caso de impago.
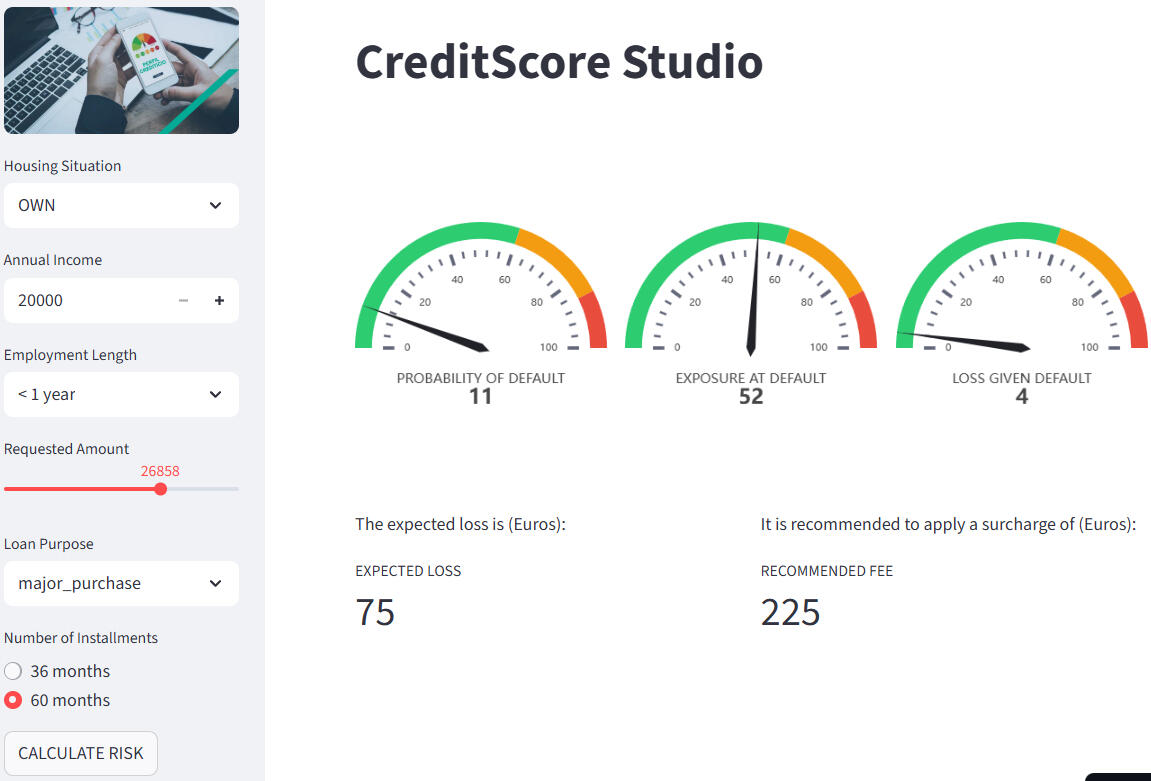
Creamos una app llamada CreditScore Studio que ayuda al banco en la toma de decisiones.
PYTHON | TABLEAU
ANÁLISIS MERCADO ALQUILER TURÍSTICO VALENCIA
A partir de datos públicos de Airbnb y utilizando Python y Tableau, evaluamos el posicionamiento del cliente frente a sus competidores, identificando patrones de precios, zonas de mayor rentabilidad y oportunidades de optimización estratégica.
EXCEL | VBA | POWER QUERY
DASHBOARD NBA
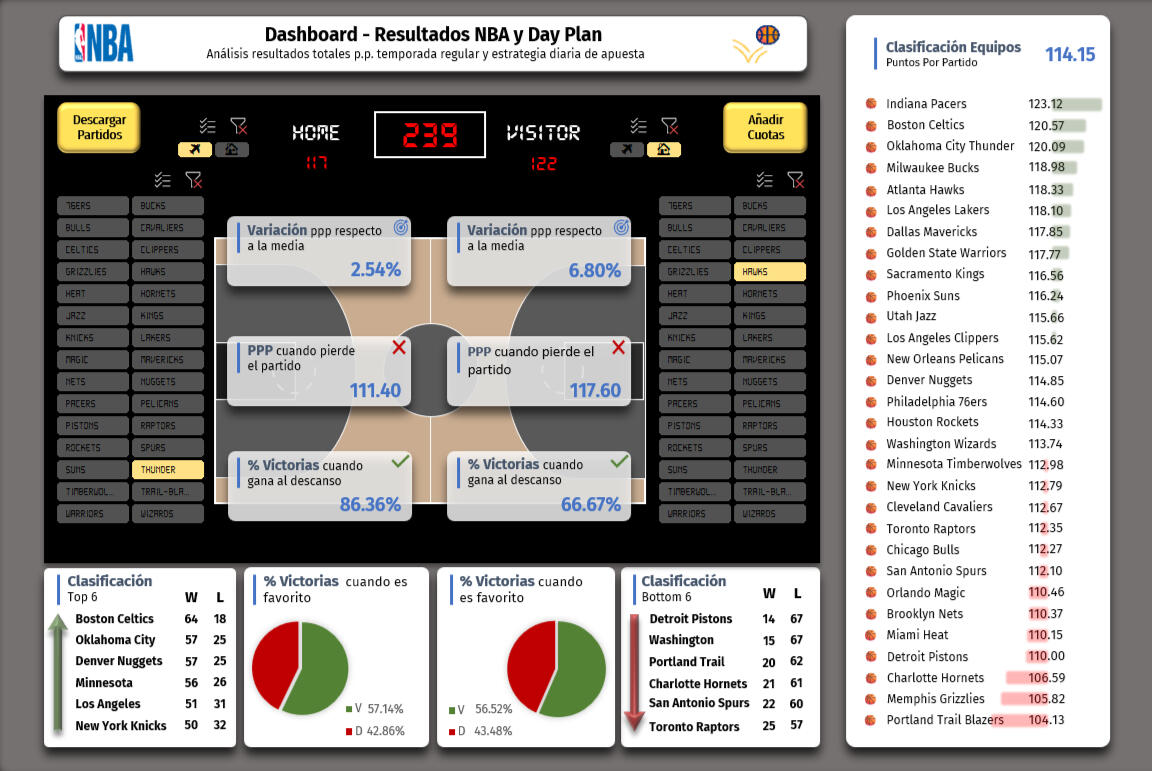
Dashboard interactivo en Excel que utiliza macros y formularios en VBA con el objetivo de ayudar al seguimiento de partidos de la NBA y para la toma de decisiones en apuestas deportivas
Ruta de Aprendizaje
PYTHON | SCIKIT-LEARN | STREAMLIT
MODELO MACHINE LEARNING SCORING BANCARIO
RESUMEN EJECUTIVO
• Un aumento de la morosidad en una entidad financiera puede deberse a varios factores, pero uno de ellos es una mala gestión del riesgo crediticio a la hora de conceder préstamos al consumo.• Como ocurrió durante la crisis de 2008, una inadecuada evaluación del riesgo puede poner en peligro la estabilidad de un banco, por lo que disponer de una herramienta robusta de análisis y modelización es fundamental.• Para abordar este reto, apliqué técnicas de calidad de datos y realicé un análisis exploratorio (EDA) utilizando la librería Pandas.• Con Pandas y NumPy definí las variables objetivo necesarias para los modelos y apliqué técnicas de transformación de datos (One-Hot Encoding, binarización, reescalado y consolidación de los datasets).• Para modelizar la Probability of Default (PD), utilicé Scikit-learn con un enfoque de clasificación mediante Regresión Logística, construyendo un pipeline completo con optimización de hiperparámetros, validación cruzada y evaluación mediante ROC-AUC.• Posteriormente, desarrollé los modelos de Exposure at Default (EAD) y Loss Given Default (LGD) mediante técnicas de regresión, utilizando HistGradientBoostingRegressor (equivalente a LightGBM en Scikit-learn) y replicando la misma metodología de optimización y validación.• Finalmente, preparé el código de reentrenamiento y el código de ejecución, que integré en CreditScore Studio, una aplicación construida con Streamlit diseñada para ayudar al banco en la toma de decisiones al otorgar nuevos créditos al consumo.
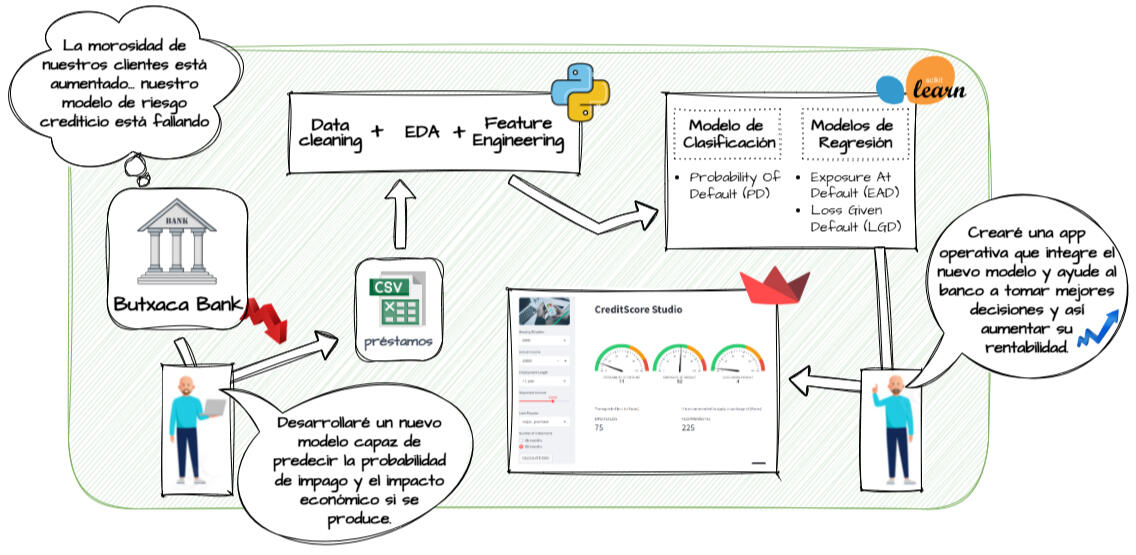
CONTEXTO
La entidad financiera La Butxaca ha experimentado un incremento de la morosidad entre sus clientes y sospecha que su modelo actual de riesgo crediticio se ha quedado obsoleto. Por este motivo, ha decidido encargarnos el desarrollo de un nuevo sistema totalmente actualizado.Más concretamente, el banco nos solicita el diseño y construcción de un sistema integral de análisis y modelización del riesgo para su cartera de préstamos personales, capaz de anticipar el comportamiento crediticio de los solicitantes, y facilitar la toma de decisiones.El objetivo principal del proyecto es dotar al banco de una herramienta orientada a negocio, capaz de determinar, no solo la probabilidad de impago, sino también el impacto económico que provocaría si ocurre.Para ello, vamos a estimar los siguientes parámetros fundamentales del riesgo crediticio:• Probability of Default (PD): probabilidad de que un cliente incurra en impago.
• Exposure at Default (EAD): importe pendiente de pago en el momento en que se produzca el impago.
• Loss Given Default (LGD): porcentaje del importe principal que se espera perder en caso de impago.
• Expecting Loss (EL): pérdida en euros que se espera cuando se produzca el impago.
DATOSLa entidad financiera nos facilita un fichero csv con su histórico de créditos personales concedidos. El fichero cuenta con 140.000 registros y 24 variables.Lo primero que hacemos es separar todo el fichero en dos datasets; uno con el 30% de los registros que lo llamamos validacion.csv; y el otro con el 70% restante que lo llamamos trabajo.csv
DESARROLLO1 - Preparación y configuración del entornoEstablecemos las librerías de trabajo y las rutas principales del proyecto.Cargué el dataset prestamos.csv, que contiene información sobre préstamos concedidos por la entidad bancaria, y definí la estructura del directorio para las fases posteriores.
2 - Calidad de datosAnalicé valores ausentes, duplicados y tipos de variables.Tras la revisión, el dataset lo dividí en dos subconjuntos:trabajo.csv (70%) para el entrenamiento de los modelos,validacion.csv (30%) para evaluar su rendimiento.Generé también versiones separadas con variables numéricas y categóricas para facilitar las transformaciones posteriores.
3 - Análisis exploratorio (EDA)Revisé las distribuciones de las variables, las correlaciones y la proporción de impagos, con el fin de comprender la estructura de los datos y detectar posibles sesgos.Este análisis sirvió para definir qué variables serían relevantes en los modelos de PD, EAD y LGD.
4 - Transformación de datosEn este notebook creé los pipelines de preprocesamiento, diferenciando el tratamiento de variables numéricas y categóricas.Apliqué imputaciones, codificaciones y escalados cuando fue necesario, y se prepararon los datasets finales de trabajo para su uso directo en los modelos.
5 - Modelización de la PD (Probability of Default)Construí un modelo de clasificación basado en Regresión Logística con regularización L1 (solver='saga', penalty='l1', C=0.25).Entrené el modelo sobre trabajo.csv y se validó con validacion.csv.Evalué el rendimiento mediante:Matriz de confusiónAccuracyPrecisionRecallROC-AUCLos resultados demostraron un equilibrio entre sensibilidad y precisión, por lo determiné que los resultados eran óptimos como base para el cálculo de la probabilidad de impago.
6 - Modelización de la EAD (Exposure at Default)Generé un modelo de regresión para estimar la exposición esperada al momento del impago.Ajusté el modelo utilizando las variables numéricas más significativas, y lo evalué con métricas de error:MAE (Mean Absolute Error)El objetivo fue obtener una predicción estable y sin sesgo excesivo, más que maximizar la precisión absoluta.
7 - Modelización de la LGD (Loss Given Default)En este notebook desarrollé el modelo capaz de calcular la proporción de pérdida esperada en caso de impago.
Utilicé nuevamente un modelo de regresión lineal, comprobando la linealidad de las variables y asegurando que los valores predichos quedaran dentro del rango [0,1].
Lo evalué con MAE y R², verificando que el modelo fuera coherente con los valores históricos.8 - Preparación del código de producciónEn este punto, integré los tres modelos entrenados (PD, EAD, LGD) en un mismo flujo.
Aquí se construyeron las funciones de predicción y se diseñó la base del sistema de producción, donde el usuario puede introducir nuevos datos y obtener los resultados de manera automatizada.9 - Código de reentrenamientoEl notebook 9 establecí el proceso para actualizar los modelos de forma periódica.
El código permite reutilizar el pipeline y volver a entrenar los modelos con nuevos datos de préstamos sin tener que reconstruir el flujo completo.10 - Código de ejecución y aplicaciónFinalmente, en Código de ejecución, se desarrolló la aplicación Credit Risk Dashboard en Streamlit.
La app permite:cargar un dataset o registro individual, generar las predicciones de PD, EAD y LGD, calcular automáticamente la pérdida esperada, y visualizar los resultados en gráficos interactivos.Este paso convierte el proyecto en una herramienta práctica, útil tanto para la validación del modelo como para su presentación.
PYTHON | TABLEAU
ANÁLISIS MERCADO ALQUILER TURÍSTICO VALENCIA
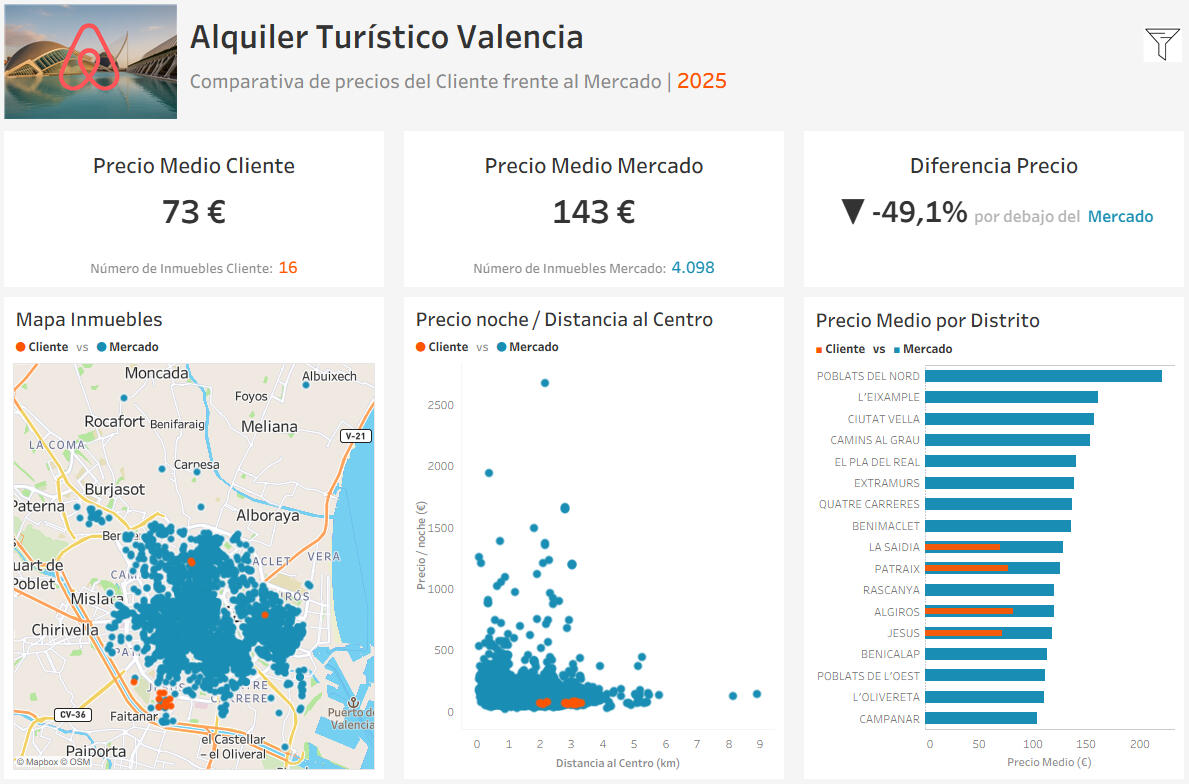
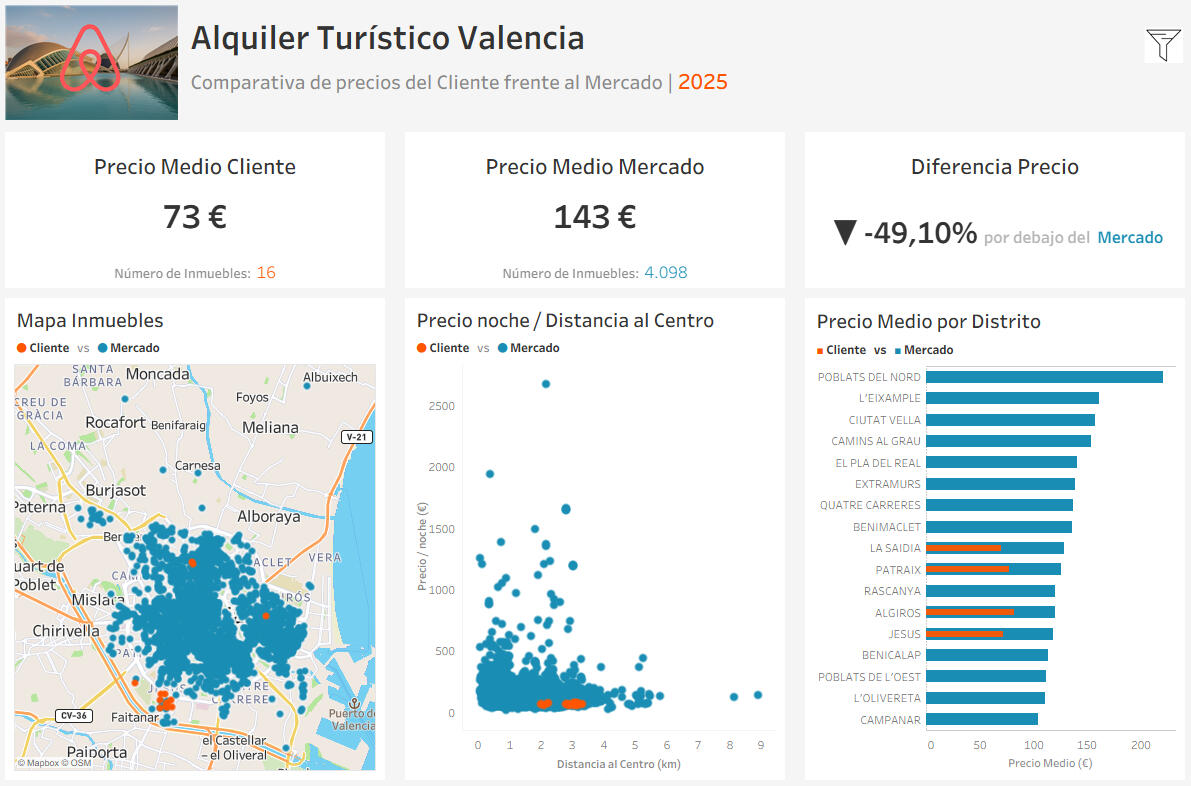
ESTUDIO DE POSICIONAMIENTO Y PRECIOS TURÍSTICOSDurante el desarrollo de mi formación en Data Analytics quise realizar un proyecto que simulase un encargo real de una empresa del sector turístico.El objetivo era analizar el mercado de alquiler turístico en Valencia para un cliente ficticio con 16 inmuebles y determinar su posicionamiento frente a la competencia a partir de datos públicos de Airbnb.El proyecto se planteó como un estudio de mercado completo: desde la exploración y limpieza de datos hasta la creación de un dashboard interactivo en Tableau, capaz de responder preguntas de negocio sobre precios, rentabilidad y localización.
PREGUNTAS SEMILLA1 - ¿Qué factores influyen más en el precio por noche de un alojamiento turístico en Valencia?2 - ¿Cómo varía el precio medio según la distancia al centro o la capacidad del inmueble?3 - ¿En qué zonas los inmuebles del cliente están por debajo o por encima del precio de mercado?4 - ¿Podemos estimar qué segmentos de oferta presentan mayor rentabilidad potencial?¿Cómo podemos presentar estos resultados de forma visual e intuitiva para la toma de decisiones?Estas preguntas definieron el enfoque analítico y marcaron la ruta del proyecto: pasar de datos sin procesar a conclusiones accionables con valor empresarial.
DESARROLLO DEL PROYECTOEl análisis se centró en entender cómo factores como la localización y la capacidad influyen en el precio medio por noche, diferenciando claramente entre la oferta del cliente y la del mercado.A partir de esta comparación fue posible detectar zonas donde los precios propios podían optimizarse para mejorar la rentabilidad sin perder competitividad.Los resultados se presentaron mediante un dashboard en Tableau, diseñado como herramienta visual de apoyo a la gestión del portafolio inmobiliario y a la toma de decisiones de pricing.
EXPLICACIÓN DEL CÓDIGOEl proyecto se estructuró en cuatro notebooks principales:1 - Diseño del caso (ver en GitHub) → definición del contexto, objetivos, KPIs y preguntas de negocio.2 - Análisis de ficheros y preparación (ver en GitHub) → exploración inicial, tratamiento de nulos y creación de variables clave como distanciaalcentro y precioporpersona.3 - Creación del Datamart Analítico (ver en GitHub) → consolidación de los datasets listings y listingsdet, segmentación del mercado, cálculo de KPIs y generación del dataset final datamartvalencia_total.csv.4 - Análisis y conclusiones (ver en GitHub) → visualización de resultados con Seaborn y preparación del archivo para Tableau.
CONCLUSIONES
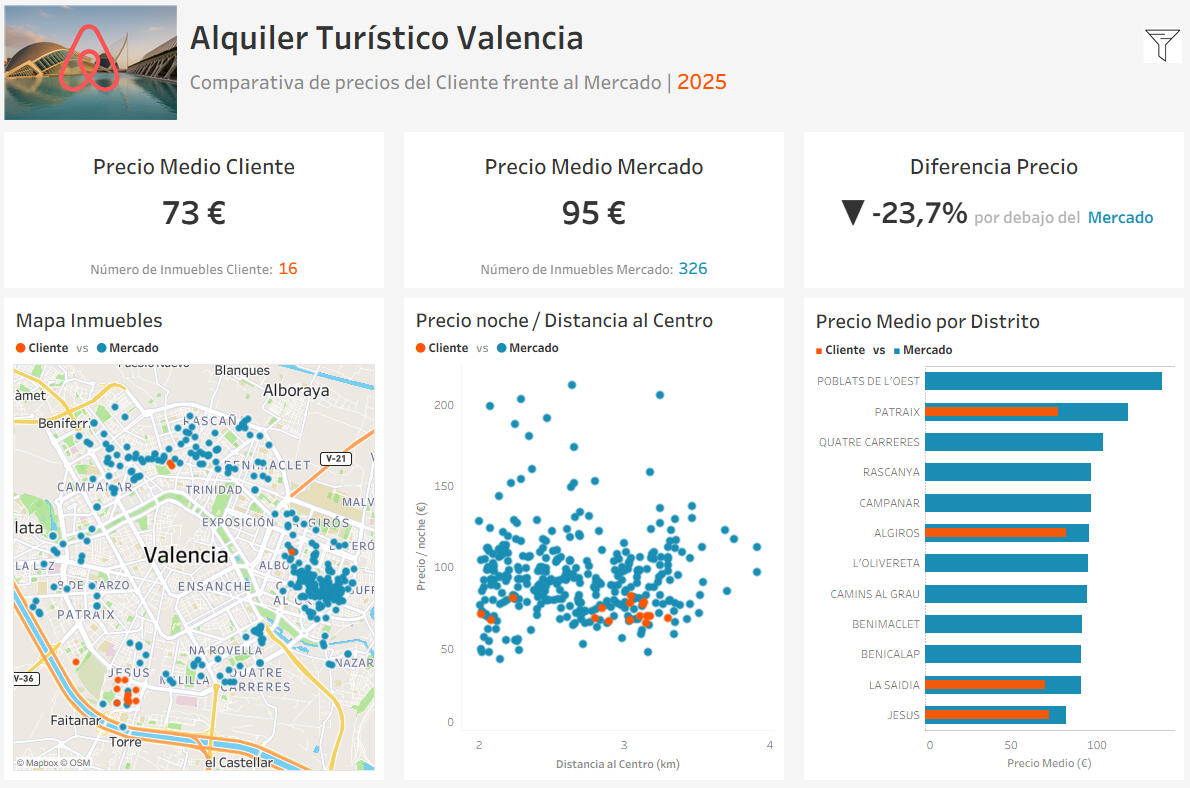
La imagen superior muestra el dashboard en Tableau, filtrado con los mismos valores utilizados en Jupyter:Distancia al centro: entre 2 y 4 kmRango de precios: de 0 a 300 €Capacidad: de 2 a 3 huéspedesDentro de estos parámetros se encuentran los 16 inmuebles del cliente, lo que permite comparar su posición real frente al mercado.Los resultados son claros: el precio medio de los inmuebles propios se sitúa aproximadamente un 24 % por debajo del mercado para propiedades con características equivalentes.A partir de este análisis, se recomienda un ajuste al alza en los precios, especialmente en los segmentos donde la diferencia con la competencia es más pronunciada.Por último, cabe destacar el carácter ficticio del proyecto: aunque se han empleado datos reales del mercado, un estudio profesional requeriría considerar también variables internas del cliente, como el estado de los inmuebles, las tasas de ocupación o la estrategia de rentabilidad esperada.
EXCEL | VBA | POWER QUERY
DASHBOARD NBA
DASHBOARD NBADurante la temporada 2023-2024 de la NBA quise crear un sistema que no solo actualizara automáticamente los resultados de los partidos, sino que también sirviera como herramienta de apoyo en la toma de decisiones para apuestas deportivas.
El objetivo era disponer de un dashboard en Excel capaz de recopilar datos en tiempo real, consolidarlos en una base de datos y facilitar el análisis de tendencias sobre el total de puntos anotados en cada partido.
PREGUNTAS SEMILLA1 - ¿Cómo puedo automatizar la descarga de estadísticas de cada partido desde una fuente web sin tener que copiar los datos manualmente?2 - ¿Podría permitir que el usuario seleccione una fecha específica y obtener automáticamente los partidos de esa jornada?3 - ¿Cómo garantizar que no se repitan datos ya descargados en la base de datos?4 - ¿Qué estructura necesito para comparar los resultados reales con las cuotas ofrecidas por las casas de apuestas?5 - ¿Sería posible analizar los promedios de puntos y detectar patrones útiles para apostar al total (“over/under”)?
DESARROLLO DEL PROYECTOEl dashboard fue construido íntegramente en Microsoft Excel, integrando VBA y Power Query para automatizar el flujo de datos.Desarrollé dos formularios interactivos:- Uno para seleccionar la fecha de los partidos- Y otro para registrar las cuotas de apuestas (local y visitante)La macro principal, DescargaResultados, se conecta automáticamente a la web hispanosnba.com, descarga las estadísticas mediante una consulta Power Query y las consolida en la hoja BD (Base de Datos).Desde ahí, el sistema:- Comprueba si la fecha ya ha sido descargada para evitar duplicados- Determina el ganador y el equipo favorito- Y guarda la información necesaria para evaluar tendencias de puntos y rendimiento ofensivo.Gracias a este flujo, el dashboard permite analizar variables clave como la media de puntos por equipo, el número de partidos por encima o por debajo del total esperado y la relación con las cuotas de apuestas.El resultado es una herramienta que transforma un simple Excel en un sistema predictivo artesanal, útil para identificar oportunidades de valor en las apuestas al total de puntos (“over/under”).
EXPLICACIÓN DEL CÓDIGOEl código VBA se organiza de forma modular:- Módulo principal (ver en GitHub): contiene las macros encargadas de la automatización (DescargaResultados, VictoriaDerrota, DeterminarFavorito, GanadorDescanso, etc.).- UserForm3 (ver en GitHub): gestiona la selección de fecha mediante listas dinámicas (día, mes y año).- UserForm1 (ver en GitHub): permite registrar las cuotas de apuestas con validación numérica.- La integración con Power Query permite importar directamente las tablas de estadísticas sin intervención manual, manteniendo la base de datos siempre actualizada.
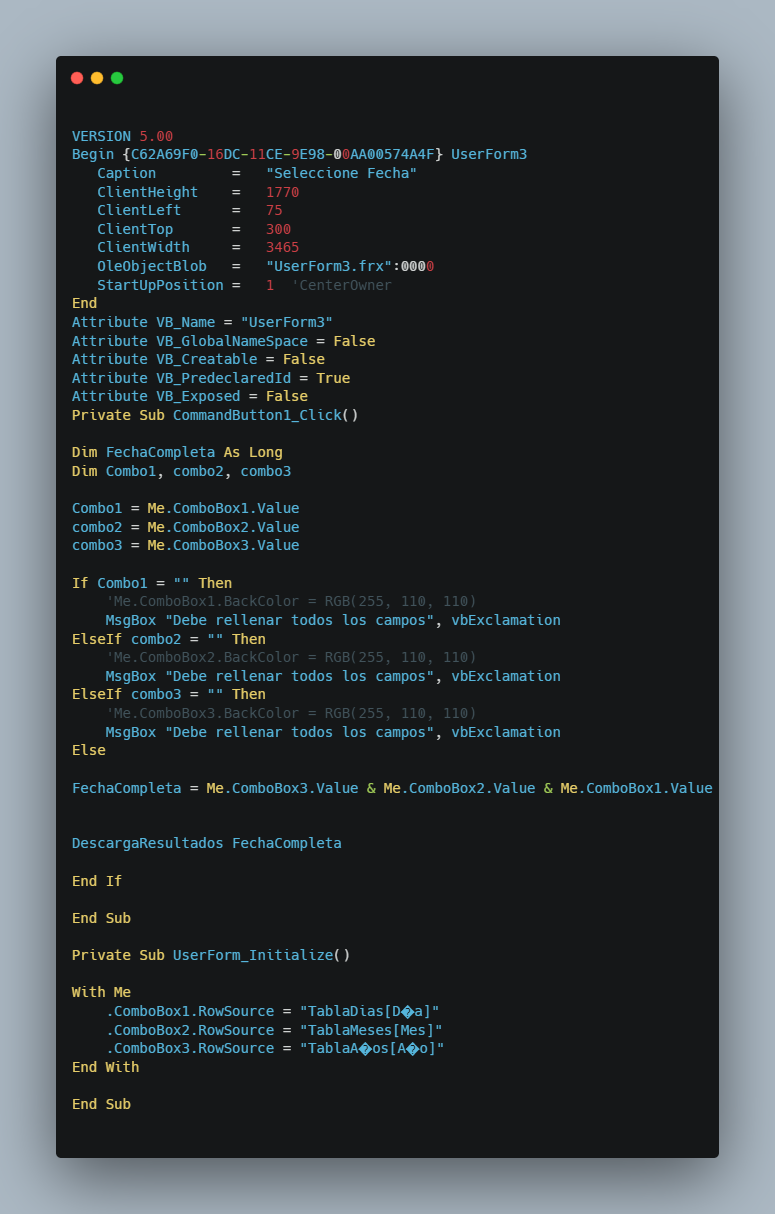
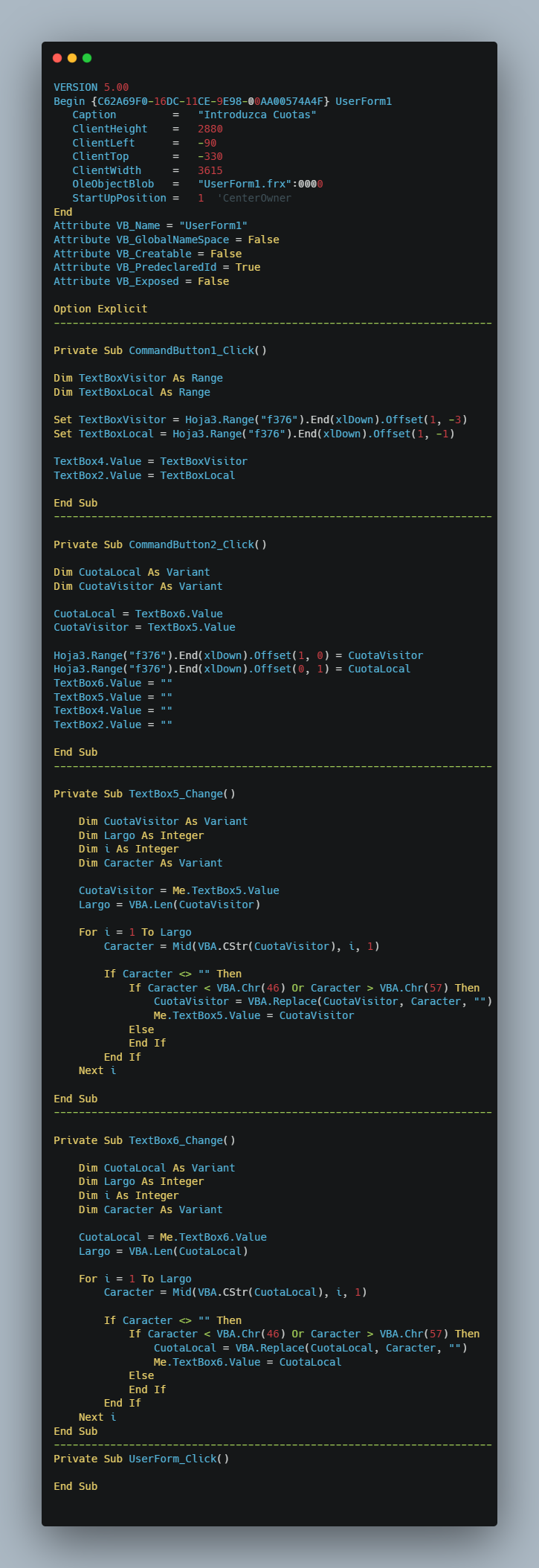

Contacto
Envíame un correo